
Every so often I will look at an AWR report for a slow system, and updates to the data dictionary table SEQ$ will show up as a top resource consumer. This is usually because sequences are defined using NOCACHE. In this post we show why this matters and how to avoid it.
In an effort to have an uninterrupted series of numbers, some database users will define their sequences to be NOCACHE. This means every time a user gets NEXTVAL, they only get, well, the NEXT VALUE, and no additional values are kept in the sequence cache in the SGA.
This can be a poor idea, for a couple reasons.
First, the Oracle 12c Release 1 Database Concepts manual explicitly states that it’s a bad idea. If a sequence number is used in a transaction that is rolled back, the result will be a skipped number.
Second, NOCACHE imposes a performance hit. Every time you get NEXTVAL, SEQ$ gets updated; those updates can be expensive. Consider this example:
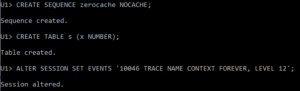
We’ve set up a NOCACHE sequence, built a simple table, and turned on session tracing.
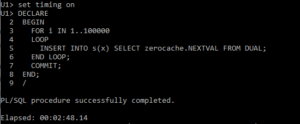
Next we do 100k inserts into our simple table, using the sequence we just built. Note this took two minutes 48 seconds.
Now let’s repeat this, but instead of a NOCACHE sequence, let’s set the CACHE to be 1000:
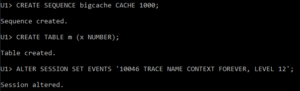
So, again, we’ve made a sequence (CACHE = 1000), built a table, and turned on tracing.
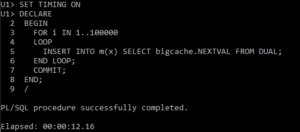
This time when we did 100k inserts, it took twelve seconds. So we’ve gone from 168 seconds to 12 seconds; an improvement in performance of over 10x. Why? Let’s look at the tracefiles.
Here’s the tracing with the cache of 1000:
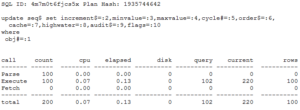
Since the cache was set to 1000, we only did 100 updates of SEQ$ which took 130 milliseconds.
Here’s the tracing with NOCACHE:
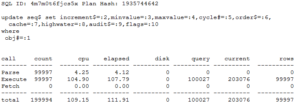
We did 99997 updates of SEQ$ which took almost 112 seconds.
Looking at the INSERT statements, the longer time for the NOCACHE sequence impacted the statements themselves.
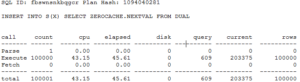
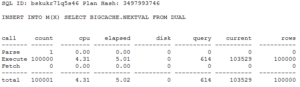
Due to the extra updates of SEQ$, the INSERTS using zerocache had to read an extra 100000 blocks in CURRENT (update) mode, which translated into a much longer net execution time.
Using a cache of 1000 might not be the best for your needs; but even using the default value of 20 is better than using NOCACHE. When you multiply this effect by dozens or hundreds of NOCACHE sequences, the maintenance of updating SEQ$ gets very costly.
Recent Comments